Fifth in a series of blog posts highlighting the personas produced in our design process, each representing a typical user of Hydra-in-a-Box and embodying a number of use cases that our repository product, now in development, or our hosted service, now in planning, aim to fulfill.
Here we meet Boyd Gordon, “the metadata guy” at a large independent research institution. He needs repository features that make the multitude of metadata tasks on his plate much faster and less cumbersome. When the Hydra-in-a-Box design team talks with seasoned digital content folks, metadata tooling and workflows are always a rich topic of discussion. Everyone has ideas for how to improve metadata work! Those conversations directly inform this persona and our ongoing plans for sophisticated metadata support in Hyku, the Hydra-in-a-Box repository.
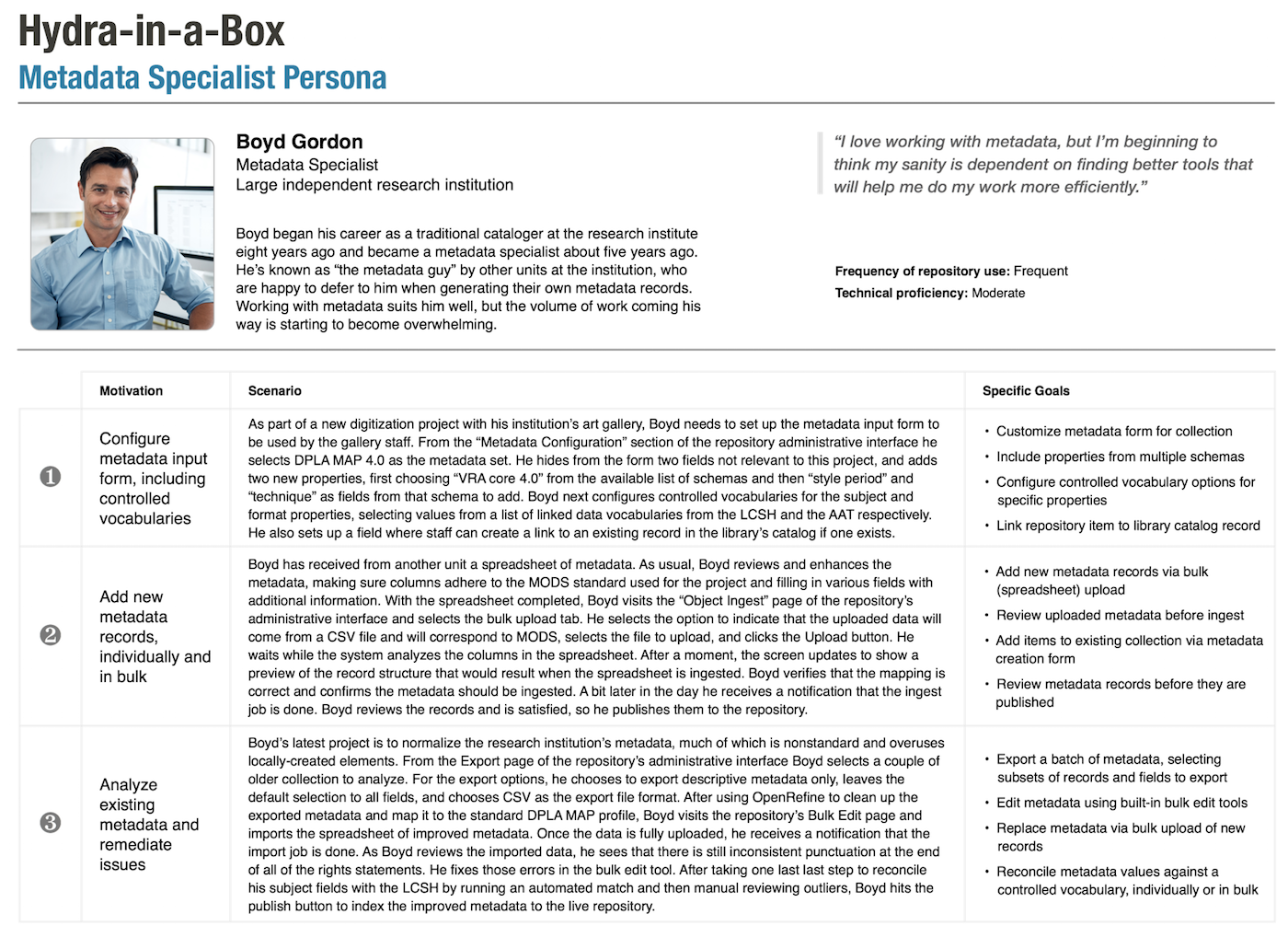
This persona document describes a number of features that will be available in the earliest releases of Hyku. For example, it is possible to import metadata records (and associated content files) in bulk via a CSV file, critical functionality for any organization looking to migrate existing collections of digital content to Hyku. Also with the newly developed, configurable multi-step workflow, it is possible for repository administrators and collection managers to review metadata that has been entered by non-specialists, making any necessary corrections along the way or sending the records back for corrections before being deposited and published in the repository.
After the release of our “minimum viable product” in just a few weeks, the development team will start to implement our design for bulk review and editing of metadata. This set of features will be extremely useful for those who need to review multiple records at a time, to quickly see if values are entered consistently and completely, and to make corrections across a set of records on a single screen.
Support for descriptive metadata record templates that are tailored to suit different content types is highly desirable. Capturing the distinctive aspects of resources – e.g., the geographic coverage of social science data sets, the duration of audiovisual media, or the coordinates of maps – benefits the discovery process for researchers searching across large collections. The Hyku repository is introducing variations in the default metadata template for deposited works, starting with image-based works. Over time we plan to add to the number of content-specific metadata templates and to augment the fields based on specific feedback from early users of Hyku.
The persona scenario also describes how it will be possible to configure controlled vocabularies, to leverage locally developed lists or external standards and linked data for use in Hyku metadata forms. This functionality is fundamental to streamlining the creation and processing of metadata so that it is high-quality and ready to take advantage of linked data. There exist already some promising efforts in the Samvera community that support this functionality, and we expect to integrate and contribute to them for broad benefit.
Coming soon: the final installment of this blog series, where we will see how the Hydra-in-a-Box repository at an academic institution supports the day-to-day work of a professor/researcher. (You can download all six of the Hydra-in-a-Box personas and other project design documents from the DuraSpace wiki.)